Theories of validity and reliability in educational assessment are explored in terms of two value systems: standardisation and classical test theory, and contextualised judgements and hermeneutic theory. It is argued that both value systems have a role in maintaining validity and reliability, but that the latter should play a greater role than in the past. A framework for analysing the validity and reliability of assessment and testing outcomes is derived from Cronbach's (1988) perspectives on validity arguments and Moss's (1994) notions of reliability warrants. To illustrate its characteristics, this framework is applied to internal assessment and external testing in Queensland senior secondary schools.
This article focusses on validity and reliability in the Queensland senior secondary school system, a system that combines internal school-based subject assessment and external statewide cross-curriculum testing. The intention is to contribute to the ongoing debate on validity and reliability in educational assessments. We do this from the perspective of theories and practices developed by the Queensland Board of Senior Secondary School Studies (QBSSSS).
Internal (school-based) assessment. Subject assessment is entirely internal (school-based). There are no subject-based external examinations. Internal (school-based) subject assessment is devised, constructed and implemented by schools. Results are certificated through a statewide program of moderation, which encompasses a set of processes including syllabus approval, accreditation of school programs of study, panels of teachers reviewing folios of student work, and approval of achievement levels for recording on the Senior Certificate. This form of moderation is referred to by Linn (1993) as social moderation.
External cross-curriculum testing. The Queensland Core Skills (QCS) Test is a statewide test of the cognitive skills that are common across the senior school curriculum. It is centrally set and administered under standard conditions (over two consecutive days) to more than 30,000 students in their final year of study (QBSSSS, 1992a). The test comprises four papers in three modes of assessment: extended writing (2 hr); multiple choice (3 hr); short response (2 hr). Candidates experience a variety of stimulus material - prose passages, poetry, graphs, tables, maps, mathematical and scientific data, cartoons, and reproductions of works of art. Any specific information required to respond to an item is contained in the stimulus material which is pitched at an assumed level of knowledge. For each multiple-choice question (MCQ), candidates choose the best response from four options. The Short Response Item (SRI) paper expects candidates to respond in a variety of ways - writing a paragraph of exposition or explanation, constructing a graph, compiling results in tabular form, showing steps in a calculation, sketching a diagram. The Writing Task (WT) tests expressive and productive skills used in composing an extended piece (about 600 words) of continuous prose in a genre of their choice.
The test is dual-purpose: it produces an overall result for each candidate; and it provides group parameters (location and scale) for all subject-groups of students in each school and for all school-groups in the State, so that subject achievement indicators provided by each school can be scaled (adjusted for fairness between different subject-groups within schools and then between schools) in the construction of a state-wide rank ordering of students (Maxwell, 1987, 1996, 1998; QBSSSS, 1992b).
Classical test theory. The psychometric model that observed score is true score plus error is based in perspectives and practices which appease the model. While these perspectives and practices may readily suit notions of validity and reliability for omnibus multiple-choice testing, they do not readily suit notions of validity and reliability for school-based assessment, nor for testing in open-ended response modes. Some of the assumptions of the true-score model are easily found not to hold for assessment involving teachers in schools: items or tasks selected at random from a universe of items or tasks; samples from an infinite population; and identical and independent Gaussian distributions. Of course, the model is considered by many to be reasonably robust to violations of the assumptions. The likelihood that an analyst will apply the model is probably related to the level of acceptance of the robustness of the model under particular violations. In our own practice we are eclectic. There are times when we apply and interpret results according to classical test theory (for example, inter-rater reliability estimates in internal assessment). There are times when we do not (for example, point-biserial correlation values as a means of identifying trial items to be discarded for the external test). We discuss both cases in this paper.
Authentic tasks. School-based learning can be realised through reading, writing, viewing, presenting, listening and doing syllabus topics. Each manner of learning is valuable, and best learning occurs when all are present. Authentic assessment emphasises doing. Consider just one of the myriad doing tasks available in school-based assessment - a Geography field study. The task is real (students experience some of the frustration and excitement of field work), the range is broad, and the skills developed in other subjects are enhanced. It also seeks to develop concern for the quality of the environment, a willingness to relate to the environment and sensitivity to conditions that enhance or threaten survival.
The stated purpose of the field study is to investigate and analyse influences on water quality, and to propose ways of dealing with problems of poor quality. The range of activities includes: site visitation; observation; collection and analysis of water and other samples; and production of a written report (see figure 1). Study of the environment is germane to Geography. A field study represents the potential of school-based assessment to contribute relevance in learning. The challenge has been to incorporate such tasks in results that contribute directly to certificated achievement and in turn to tertiary selection considerations. The worth of tasks like the field study seems indisputable, the authenticity undeniable and the contribution to the learning of students irreplaceable.
| THE TOPIC: People and the environment
THE AIMS: To investigate the water quality of a local creek with a view to determining human impact on this aspect of the local environment, human influences on flora and fauna along the course of the creek, and to analyse possible conflict between people and their environment with a view to proposing possible means by which existing problems can be decreased, and future problems avoided. THE CONTEXT: The following activities will be undertaken: observation and descriptions of the water and surrounding land environment of selected sites; water samples collected at each site tested for: level of dissolved oxygen; pH level; biochemical oxygen demand; temperature; presence of phosphorus and nitrates; turbidity. THE TASK: Compile a report on the impact that people have had on the water quality of the creek. Include in your report the results of any tests that were undertaken to determine the water quality, and report on the methods by which these tests were done. The conclusions you derive should focus on the land use practices employed by people in the Slacks Creek catchment area (and their resultant effect on water quality), and therefore indicate a knowledge of the land uses in this area. Appropriate recommendations for land use practices that will ensure better water quality should also be made. |
Abundance of information. Goals of instruction are outlined in the Geography syllabus in terms of course objectives. The domain of assessment is specified in a criteria and standards schema. A criteria and standards schema is an elaboration of each of a number of standards along each of a number of criteria or performance dimensions. Matching a piece of a student's work with one of the standards classifies the work in the range of performances from lowest to highest proficiency (McMeniman, 1986). For Geography, the criteria and standards schema elaborates five standards in each of four criteria: knowledge; comprehension, validation, application and analysis; synthesis, evaluation and decision making; and research and communication. The criteria are the global aims stated in the syllabus. There is a clear relationship between the syllabus-specified assessment domain and criteria used by schools for assessing performance in particular tasks. This relationship is illustrated by the criteria sheet handed to students before undertaking the field study (see table 1). The focus on generalised assessment criteria is clear, but so too is task specificity. The relationship between demands and delivery, syllabus goals and profile information, is conspicuous: syllabus goals --> criteria and standards schema --> task criteria sheet --> profile.
Student performances are assessed in terms of the criteria shown in table 1. As tasks are completed, a profile of information about the performance of a student is created. A profile empowers students with knowledge of how a decision about a performance affects each criterion's representative standard and the level of overall achievement. School policy and syllabus statements are used to determine levels of achievement in Geography. As results accumulate, students are aware of the current standard on each criterion and their current level of achievement. Students are also aware of areas where improvement is possible and where action which may result in improvement can be taken.

Basically, achievement at a particular level requires a majority of criterion-performances at some particular standard and no performances at more than one standard lower. Table 2 shows a profile of achievement for one student. The criteria are taken directly from the syllabus. Standards achieved are recorded as A, B, C, D or E. Achievements in formative assessment tasks are shown in lower-case, and achievements in summative tasks are shown in bold, upper-case letters. The thick vertical lines represent reporting periods. For each reporting period a representative standard on each criterion and an overall achievement level are decided. This student's profile shows overall achievement at the first reporting period as VHA (a majority of representative standards at the A level and none lower than B). In the next reporting period and three subsequent periods, the overall achievement dropped to HA, and in the final period the student's overall achievement improved to VHA.
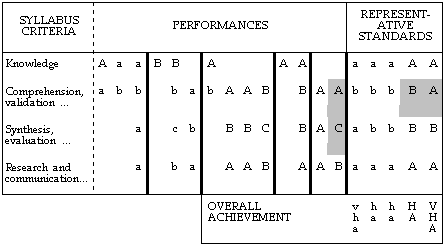
The abundance and the cumulative nature of the information in the profile provides a demonstration of the transparency of this approach to assessment. The profile in table 2 shows a case where improvement in one criterion, while maintaining achievement in others, results in a higher achievement. The profile shows that the student has improved her representative standard in comprehension, validation, application and analysis (by performing at an A level in the last assessment task) and has maintained standards in the other criteria. Had the C in the final synthesis, evaluation and decision-making task not been achieved, the representative standard, B, would not have been achieved, and the final VHA would have been in doubt. As it stands the student's final overall achievement improved from High (HA) to Very High (VHA). In this way, profiling school-based assessment encourages teachers to involve students in interpretation and management of their progress.
Generalisation across tasks. Social moderation utilises teachers' contextualised judgements to make decisions about relative achievements of students. In such a program, 'inconsistency in performance across tasks ... becomes a puzzle to be solved' (Moss, 1994, p. 8).
Judgements of overall achievement are based on folios of student work. Teachers generalise across tasks in the folio. The puzzle to be solved about inconsistent performance in school-based assessment requires an interpretation of the folio in context. Only the teachers involved in that context have access to all the information needed in solving the puzzle.
Although consistent high performance is easily favoured over inconsistent performance, the question arises about which to favour between inconsistent performance and consistent performance at some lower level. Syllabus documents state general guidelines about which criteria, if any, are favoured over others. The puzzle often reduces to judging a representative standard in each of a number of criteria and applying a set of procedures for combining these standards, revisiting as necessary the context in which each standard was set and achieved. The final level of achievement decided for the student whose profile was shown in table 2 is a demonstration of the type of generalisation across tasks that teachers make. In this way, teachers make contextualised judgements to solve the puzzle of generalisation.
Generalisation across assessors. It is not always necessary to have agreement among assessors. Moss (1994, p. 9), citing Scriven (1972) and Phillips (1990), points out that 'consensus ... is no guarantor of objectivity [and] ... objectivity is no guarantor of truth'. However, where consensus among experts is sought, the level of agreement should be measured and reported. Two recent evaluations provide information about the level of consensus in the Queensland program of moderation - one between expert panellists and the other between teachers and expert panellists. The former is a study conducted by Masters and McBryde (1994) and the latter is a report on random sampling of student scripts as part of the moderation program's quality assurance procedures (Travers & Allen, 1994).
Both studies measured the level of agreement between raters of student folios. For evaluating the level of success of the moderation program in providing levels of achievement that are comparable across schools, classical test theory provides measures and standards which have accepted meaning and interpretation. One of these is an inter-rater reliability index. Masters and McBryde (1994) used this measure in a study of the comparability of teachers' assessments of student folios. Another is the distribution of differences between school ratings and expert panellist ratings of student folios. Travers and Allen (1994) examined and reported the distribution of these differences.
In the Masters and McBryde (1994) study, 546 student folios were each rated independently by two markers under each of three models. In the first model, folios were organised in school groups and markers worked without reference to the school's assessment criteria. In the second model, folios were organised in school-groups and markers were able to refer to the school's assessment criteria. In the third model, folios were distributed at random to markers and markers were not able to refer to any school's assessment criteria. For each model, the inter-rater reliability index was .94. Figure 2 shows a plot of pairs of ratings from the independent markers for Model 3. Lines are drawn to mark where differences in ratings are ± half a level of achievement (± five points on the scale) and ± one level of achievement (10 points on the scale). (The 50-point scale derives from an assumption that achievement in each of five levels (VHA down to VLA), each categorised into 10 bands, represents interval scale data). Masters and McBryde (1994, p. vi) concluded that these estimates represent 'an exceptionally high level of agreement ... between [assessments]. These levels of agreement are significantly higher than the levels ... typically reported for independent assessments of student work - including independent assessments of [external] examination performances'.
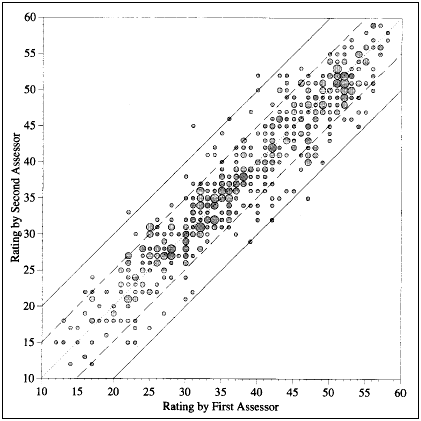
Figure 2: Pairs of ratings from independent markers
(from Masters & McBryde 1994)
In the study reported by Travers and Allen (1994), one of the analyses examines the distribution of differences between school and panel ratings (on a 50-point scale as used by Masters and McBryde, 1994) of student work folios. Taking the view that both sets of judgements (school and panel) are estimates of the true score of a folio, then the distribution of residuals (differences between school and panel judgements) shows a comforting degree of symmetry and a more comforting degree of kurtosis - residuals are more tightly clustered around the mean than they would be if errors in estimating true score occurred at random and were normally distributed (see figures 3 and 4).
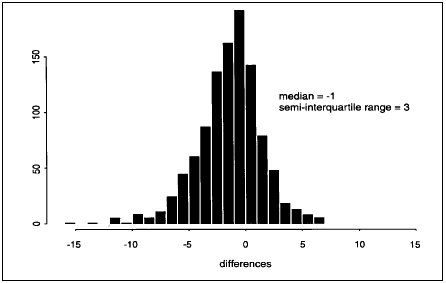
Figure 3: Distribution of residuals (differences between school and panel judgments)
(from Travers & Allen 1994)
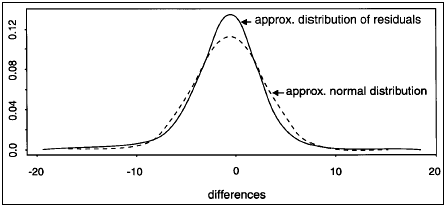
Figure 4: Approximate normal distribution superimposed on the approximate
distribution of differences shown in Figure 3 (from Travers & Allen 1994)
Gender bias. Within the political perspective one category of questions that can be asked about a test encompasses questions about fairness. The issue of fairness is a highly charged one and of great importance to the stakeholders. One definition of fairness is the absence of bias. In our quest for fairness we inspect items and we study group differences.
Because bias can occur as a result of representing groups in stereotypical or patronising ways - and this can present at the item level or even permeate test papers - item writers are sensitised to the many ways they may inadvertently introduce bias when composing items. Also, the test development team convenes meetings in order to assess range and balance across the four papers that comprise any one version of the QCS Test.
Even though we consider all test developers and teachers to be equity practitioners who therefore have a responsibility in this area, we seek expert advice to sensitise us to items that are potentially flawed in an equity sense. We convene an equity panel with a charter to provide advice representing any of four considerations - cultural, gender and social justice, content and construct or design (O'Connor & Robotham, 1991).
Admittedly, there are complications as the task of attempting to make such judgements 'is made especially difficult because of the implicit and emotional assumptions people make that lead them to view the same information in different ways' (Cole & Moss, 1989, p. 201). It is especially the case that when the group is identified by gender or race, different observers bring different values.
In investigating gender bias empirical evidence is necessary - data from pretest and post-test analyses. We take the view that differential item functioning (DIF) does not automatically indicate bias but rather that bias 'is a difference which cannot be defended' (Wood, 1991, p. 180).
Allen (1988, p. 16) observes that females and males in Queensland take part differently in senior education: 'a different proportion of the underlying population signs up for different subjects in different numbers and achieves different results'. Recent analyses, by gender, of retention rates, curriculum patterns and achievement distributions indicate that this observation remains legitimate. This being the case, males and females bring to the QCS Test their different backgrounds. One interpretation of items that exhibit DIF is that differential performance by gender reflects this difference in backgrounds. A charge of bias must therefore be questioned when it is possible that different performances merely reflect an underlying reality.
Discarding items with varying difficulty for different subgroups of the population, an extreme solution, is not considered to be the answer. We take Angoff's (1993) view that an equitable test is one in which DIF, if it can be shown to exist, is balanced over the subgroups exhibiting DIF.
We use two statistics in our search for DIF by gender. One, the Hoover-Welch (HW3) statistic, is an optimally weighted t-statistic aggregated across ability levels. The other, the generalised Mantel-Haenszel (MH) statistic, is a chi squared statistic capable of handling the k (separate ability levels) x 2 (subgroups) x g (score categories) contingency tables resulting from an SRI (Agresti, 1990, cited in Welch & Hoover, 1993).
We choose to examine co-plots of MH and HW3 seeking oddities in the distributions, rather than apply statistical tests of significance. Items exhibiting DIF on both measures appear at the extremes of the distributions. Figures 5 and 6 plot MH statistic versus HW3 statistic for items in the 1994 QCS Test. The item identifiers, 1-100, refer to MCQs; 101-123, to SRIs.
Figure 5 plots the MCQs only. Ignoring population differences, it could be interpreted that MCQs favour males. Figure 6 plots all items - MCQ, SRI, WT. When all items are considered together, because of the larger scale of SRI and WT scores, these items predominate in apparent DIF - which is precisely the reason for using the HW3 statistic. Student performance on the test is reported as one of five grades and these grades are based on the total score; where an item exhibits DIF, the relative worth of that item's contribution to total score is fundamental to providing a balance. In general, the test appears to be fair by virtue of the 'balance' in DIF. The WT contributes significantly to the balance by countering any 'imbalance' from the contributions of MCQs and SRIs.
Figure 5: MH statistic versus HW3 statistic for MCQs in 1994 QCS Test
The phenomenon of balance and counterbalance is not surprising. In a multidimensional test, which is what the QCS Test is designed to be, DIF is to be expected insofar as, in the Queensland situation, gender and curriculum experience are related. To remove items that might provoke claims of bias against certain subgroups of the population would be to deny that students come to a truly cross-curriculum test differently equipped in terms of their experience of the curriculum. That is, solely by virtue of their subject choices, there are students with differing learning opportunities who approach the test differently. This has significant implications not only for the test design and construction but also for the application and interpretation of item (and test) analyses.
Figure 6: MH statistic versus HW3 statistic for all items in 1994 QCS Test
Both empirical evidence and inferences that go beyond the data are necessary before any conclusions can be drawn about bias. If, after sensitive analysis, DIF can be explained by some plausible hypothesis other than subpopulation differences, the item is accepted as unbiased.
We now discuss gender bias with respect to the subtest that tests writing ability. The WT is presented to students as a collection of pieces of stimulus material, both textual and pictorial, linked by a common theme. Students have two hours to respond to aspects of one or more pieces of the stimulus material by writing about 600 words of continuous prose in the genre that they choose. The stimulus material is accompanied by some writing suggestions.
Given the data provided about the performance of females on the WT, it is interesting to note that there are pressures on us, stated as an equity issue, relating to the accessibility (to females) of the stimulus material. Equity considerations are implicit in the fact that the QCS Test comprises test papers in three different modes of response. To avoid the possibility that specific decisions relating to the stimulus material might act counter to the more global equity considerations, it is clear that equity issues must also be allowed to impact on the choice of stimulus material, whether it be of each individual piece or of the nature of the collection.
We have developed guiding principles for deciding on the appropriateness of an individual piece of stimulus material. It must be taken into account that students belong to more than one of the equity categories (race, ethnicity, culture, gender, disability, socioeconomic class) and that texts and pictures are open to a broad range of explicit and implicit meanings. A piece that is ostensibly about boys and science may offer a wide range of meanings to girls and boys from diverse groups and should not be rejected uncritically simply because a single connection may have been inferred.
In fact, affirmative action may well be undermined by making selections that are founded in classifying people according to their 'victimhood'. A consequence of precluding a piece on boys in science, or science generally, might well be to prevent girls who are interested in it from responding to a piece of stimulus material in their preferred domain - hardly a favourable outcome in terms of the desire to encourage greater participation of girls in science. Similarly, one would not exclude an extract that relates to a disease on the basis that some students might be afflicted with it - immediate exclusion could very well be an act of prejudicial condescension that fails to recognise that sufferers of this disease, or any other for that matter, might choose to exploit their heightened sensitivities to the effects of disease by responding to such a piece. It would be similarly perverse to stereotype girls, for example, in terms of their dominance in the private worlds of relationships, in an attempt to counter the negative influences of stereotyping. Girls must be given the opportunities to write in ways other than those that are based on explicit representations of their private worlds. Hence, the choice of individual pieces and writing suggestions cannot be dominated by any equity-related assumptions, such as that girls typically value relationships over tangibles and abstract ideas.
There must also be an awareness that the test setters' choice of stimulus material and the candidates' choices of response genres are not independent - some pieces of stimulus material invite responses in particular genres. Hence, to narrow unnecessarily the range of stimulus material may not just narrow the content of responses, but also act counter to the ethos of the WT by restricting the freedom of students to write in genres of their choice.
The issue of genre choice was, in fact, the major focus of Crew and McKenna (1993) who investigated the hypothesis that 'female narrative texts' are devalued by test setters and markers. Results of their research, while supporting the view that, in an open-genre task, diaries, journals and letters do not score highly, are open to interpretations that are not genre-based or gender-based. Even were it true that (in the eyes of markers) 'all genres are equal', it may not be true that all genres are handled equally well by students or that the selection of particular genres is independent of overall writing ability. Hence, it is not simply a matter of saying that writing by girls about their private worlds is valued less than writing by boys about the public arena. Further, any such conclusion might also need to take into account even wider equity issues, such as the possibility that the over-representation of females among the WT markers itself influences the WT results.
It is clear that the key to resolving equity issues in the WT lies not in any 'Orwellian' censorship of individual pieces of stimulus material, which can only lead to a WT so sanitised as to have become bland and irrelevant to its purpose. Rather, the key is the judicious assembling of the collection of pieces. The face validity and the testing validity of the WT are preserved through balancing the degree to which the elements of each equity category are represented and the ways in which they interact. When the pieces of stimulus material are taken from literature and the humanities, care is taken to sample from among the many cultures, both within the whole test each year and across the years.
The working out of equity considerations in the WT is necessarily different from that for the SRI and MCQ testpapers, where the ideal is that all students can access every item. The aim for the WT is that every student can find accessible and interesting pieces of stimulus material that allow them to write in their preferred genres. At the end of the day, many and varied pieces of stimulus material are presented to students. Each student need only find one accessible piece, and most find several, to be able to formulate a response.
Propriety of testing particular skills. We describe one incident involving our test development unit, a group of senior teachers, a school principal and an academic (in linguistics). It was demanded that we suspend the preparations for SRI marking, pending consultation about one of the items on the SRI subtest. This item explicitly tested the common curriculum element (CCE) using correct spelling, punctuation, grammar, one of 49 CCEs which were identified in a scan of the senior curriculum as being common across the curriculum (within the learning experiences of at least 95 per cent of students) and testable given the three modes of assessment available (Allen, Matters, Dudley & Gordon, 1992). The demand was based in objections that the context in which 'a word has been wrongly used' (there were seven instances) does not sanction describing alternative usage as grammatically correct. Specifically, the objections involved having students correct the use of reflexives in coordinative constructions and the use of a plural verb with the 'neither ... nor' construction containing singular noun phrases. The stem of the item in dispute is reproduced in figure 7.
We continued to train the markers. We responded to the letters of demand by saying that we did not make lightly the decision to include this item. In fact we chose to do so mindful of its potential to produce a negative reaction from some. We understand that regardless of the high quality of advice we receive from teachers, academics, linguists and editors on our panels (subject expert, equity, editorial, scrutiny), all material we use will not be equally acceptable to all in the teaching profession. Currently, there is a debate about functional versus traditional grammar. This debate involves differing philosophies of teaching English. It is not a debate about the CCEs that are to be tested in the QCS Test. We chose to put before the candidates the concept of correctness - a concept that seems threatened but one which many teachers believe is worth defending.
In our dialogue with the five schools concerned, we argued that, because the QCS Test is a cross-curriculum test, CCEs cannot be perceived as belonging to particular subjects. Using correct spelling, punctuation, grammar does not belong to the subject English any more than another CCE, sketching/drawing, belongs to the subject Art.
This response seems to us to accord with the expectation Cronbach (1988) has about dispute. While there may be no single, clear, correct answer, the position of the test development agency is to acknowledge community dispute and to have a defensible position. (Most schools, by the way, did not need persuading.)

Figure 7: Stem of Item 6, Unit Four, SRI paper, 1994 QCS Test
We have explored internal-consistency reliability estimates of the 1992 version of the QCS Test (QBSSSS, 1992c) in terms of three distinct types of measure: Horst's (1951) measure and KR-21 (both appropriate for the 100 MCQs only), Cronbach's coefficient alpha, and two congeneric measures due to Gilmer and Feldt (1983).[1] Analyses were conducted on different partitions of the test - different in terms of the number of partitions, in terms of the number of items in a partition, and in terms of the different purposes for partitioning - seeking to exploit differences in coefficients which may be due to the non-tau-equivalence of the parts (O'Brien, Pitman & Matters, 1996).[2] The results show that the 1992 version, replete with SRIs and involving a single yet relatively high-weighted WT result, produced an on-average reliability of approximately .87. This result, however, is not the complete story (see later).
We now turn to three aspects of reliability warrants: item difficulty; item and partition correlations; and test and item characteristics.
Item difficulty. For the 1994 QCS Test, the average facility on the MCQ subtest was .61 (no correction for guessing), on the SRI subtest .54, and on the WT .49.[3]
In attempting to answer questions about what makes an item difficult, one suggestion is that difficulty may be due to three factors, alone or in combination: the nature of the cognitive task (intrinsic difficulty); student perception of the difficulty of the task (self-imposed difficulty); and aspects of test design (design-imposed difficulty).[4] Here, we touch on self-imposed difficulty. Self-imposed difficulty is defined as being a function of a particular student's mind-set on viewing the stimulus material.
If a student's perception of success is influenced by features of the stimulus material such as content and context, then this is a particularly potent influence in a cross-curriculum test where CCEs that are traditionally taught and learnt within certain subjects are tested within the epistemic content of other subjects. Some students perceive disadvantage to exist in terms of superficial 'subject-ness'.
For an item in the so-called 'opera unit' on the 1994 SRI paper (QBSSSS, 1994), the primary CCE being tested was deducing, which is high on the list of higher-order cognitive skills. The item even read 'assemble the clues'. This analytic CCE was tested within pretty and soft stimulus material. The percentage of non-contributory responses on this item, and on two other items in the same unit, was very high (32-38 per cent). Anecdotal evidence confirmed our suspicion that there was a substantial group of students who did not attempt the unit.
Did those students perceive the unit to test the subject Music? If so, their failure can be explained in terms of self-imposed difficulty. Studying Music would be advantageous only to the extent that students allow their perception of the task to be influenced by the epistemic area in which it is set.
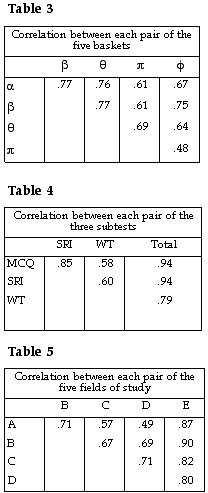
Item and partition correlations. Meaningful partitions of a test are those that serve some particular purpose. There are three meaningful partitions of the QCS Test: 1) baskets (of items); 2) subtests; 3) fields of study. The five baskets provide a shorthand description of the domain of the test, yield a practicable set of criteria and standards for informing the process of arriving at cutoffs for reporting student results, and provide an additional means for assessing the range and balance of the items in any particular test (Matters & Gray, 1993). Each basket represents a reasonably coherent set of CCEs. Basket alpha is comprehend and collect; beta is structure and sequence; theta is analyse, assess and conclude; pi is create and present; phi is apply techniques and procedures. Subtests are the three modes of response: multiple-choice; short response; extended writing. Fields of study are defined so that information can be provided about group performances in five areas of study, each of which emphasises the skills within the definition of that field: field A is extended written expression; field B is short written communication; field C is basic numeracy; field D is solving complex problems; field E is substantial practical performance. In partitioning the test into fields the aim is to maintain low correlations between fields while maximising the reliability of each field.
Correlations (Pearson product-moment) between the three meaningful partitions of the test are shown in tables 3 - 5. There are no surprises in the values in the tables. For example, the relatively low value (.48) for the correlation between baskets pi and phi should be expected, given the nature of the CCE's (and items) represented in those baskets. In a similar way, field A would be expected to have a relatively high correlation with field B and a relatively low correlation with each of fields C and D, given the skills emphasised by the fields.
Test and item characteristics. In the case of an external test, solving the puzzle of inconsistent performances involves analysing item characteristics and test design characteristics in the search for plausible accounts of differences and involves pretest analysis of trial items, refinement of items and post-test analysis of items.
Items, both MCQs and SRIs, are trial-tested on populations in school systems other than our own. The following discussion refers to MCQs only because the information gleaned from trialling SRIs is different in nature. At the first level of analysis of trialled MCQs, items are checked against the classical expectation that they discriminate between the better candidates and the not so able, positively in the case of the keyed option and negatively in the case of each other option.
The use of the point-biserial correlation of trial item with trial total score as a tool for reviewing items after trial and for guiding the selection of items for any given version of an MCQ subtest proceeds, but with several reservations in mind. First, the trial population may be distinctly non-Gaussian in terms of the characteristic of interest. Second, the selection of items could inadvertently be biased in favour of a particular narrow type of item, as in the following scenario.[5]
Suppose that trial items include a large proportion of quantitative (Q) items that do not exhibit local independence within units and are highly correlated between units. Suppose on the other hand that the verbal (V) items are highly heterogeneous - a desirable property in the case of the QCS Test, where item writers are expected to explore a wide range of possibilities. In spite of this, the Q item writers maintain what they believe to be a successful approach - at least in the scenario being painted here. Then, according to the mechanistic approach for selecting items (on the basis of 'good' point-biserial values), only those V items that 'line up' with the majority of the Q items would be selected to appear on the test. The subsequent unidimensionality of the resultant test would be an artefact of the homogeneity of the Q trial items, itself a function of a certain approach to item writing.
Unidimensionality, coveted by many, would be an outcome. But the existence of unidimensionality does not establish that the single dimension is the required dimension. In fact, in the case of the QCS Test, what is required is a set of items measuring a complex of abilities: in the QCS Test, by design, the items do not aim to measure the same composite of abilities.
There is a third reservation. In our view, inferior trial statistics do not necessarily invalidate an item. Rather, student performance on the item becomes a puzzle to be solved by searching for a comprehensive interpretation that explains the inferior statistics or articulates the need for additional evidence. Our policy is in line with Cronbach's (1990, p. 178) view that rejecting unusual items '"purifies" the test, but the instrument then no longer represents the intended domain'.
It is our policy that there may be a place in the test for difficult items (facility below .25) and for easy items (facility above .75) for reasons not explained here, and even for one (out of a hundred) from a special class of difficult item: an item with a negative point-biserial value for the key. For example, after examining the item characteristic curve (ICC) for trial item number 64, shown in figure 8, and in the absence of a label on the option which is the key, one would probably think that the key is A and that this is a properly functioning item. In fact, the key is C. Note the interesting flip upwards on the C-graph at the high-ability end.
Figure 8: ICC of trial item number 64
Maybe ICCs cannot be considered as definitive in making decisions about whether or not an item 'works'. In a test of academic achievement there might be, as there is in the case of trial item number 64, a more elevated explanation for the value of the point-biserial correlation - that good students made the classic error in a classic problem and were seduced by an attractive distracter. Those test setters for whom the key is verified according to which option provides an appropriate point-biserial value or ICC are on dangerous ground.
Does this ICC represent the 'sharp end' of the validity-reliability impasse? Certainly, if an incorrect option is attractive to the high scorers the item should be reviewed. Should it necessarily be discarded?
| THE THREE SUBTESTS | COEFFICIENT a | NUMBER OF ITEMS |
| MCQ | .92 | 100 |
| MCQ + SRI | .94 | 124 |
| MCQ + SRI + WT | .87 | 125 |
Our policies, briefly described in part in this paper, realise a reliability coefficient of .92 for MCQs. When the 24 SRIs are included, the reliability rises to .94.[6] It is only after including the WT score (a single item contributing, because of its scale, a large amount of variance to the total score) that reliability drops below the 'magic' level of .90. Before reaching a pre-emptive conclusion that the WT subtest should be dropped from the QCS Test, it would be well to consider these points: the inclusion of the WT is a curriculum issue because the QCS Test is required to reflect things learnt and valued in the curriculum; the WT 'balances' the apparent gender difference in performance on MCQs and SRIs; the WT provides a large degree of face validity of the QCS Test; the magic level is based, historically, on explanations of omnibus, multiple-choice tests; the magic level, if deemed desirable, could be achieved by reducing the weighting of WT scores towards total test score.
The complete story of validity and reliability cannot be told in this brief paper. We have chosen to focus on just two of Cronbach's (1988) validity perspectives: functional and political. The story is seriously incomplete without arguments in other perspectives, in particular, without arguments in the explanatory perspective. It is in this perspective that arguments relate the two high-stakes regimes to each other.
Two estimates of a student's overall achievement in the senior curriculum are QCS score (already mentioned) and Within School Measure (WSM). The WSM is an estimate of a student's overall achievement based on teacher-decided rank order information in school-based assessment. The measure makes use of paired comparisons between students to compile an overall indicator of achievement within a school. Overall achievement as measured by QCS score and overall achievement as measured by WSM can be compared and large differences identified.[7]
The Pearson product-moment correlation of QCS score with WSM is .74. This relates the two sets of assessments, one from the internal system, one from the external system, and is a precursor to many other arguments in the explanatory perspective.
As educational practitioners we are interested in the nature of learning and in the outcomes of teaching and learning. The validity of learning outcomes is assured by valid assessment practices, and valid assessment practices, we believe, result in reliable assessments.
Neither a psychometric nor a hermeneutic approach to reliability guarantees fairness. A consideration of the assumptions and consequences associated with both approaches leads to a better informed choice.
Allen, J. R. (1988). ASAT and TE Scores: A focus on gender differences. Brisbane, Queensland Board of Secondary School Studies.
Allen, J. R., Matters, G.N., Dudley, R.P. & Gordon, P.K. (1992). A Report on the scan of the Queensland senior curriculum to identify the common elements. Brisbane: Queensland Board of Senior Secondary School Studies.
Angoff, W. H. (1993). Perspectives on differential item functioning methodology. In P. W. Holland & H. Wainer (Eds), Differential item functioning. Hillsdale, New Jersey: Lawrence Erlbaum Associates.
Calfee, R. (1993). Assessment, testing, measurement: What's the difference? Educational Assessment, 1(1), 1-7.
Campbell, D. T. (1986). Science's social system of validity-enhancing collective belief change and problems of the social sciences. In D. W. Fiske & R. A. Schweder (Eds), Metatheory and subjectives. Chicago: University of Chicago Press.
Cole, N. S. & Moss, P. A. (1989). Bias in test use. In R. L. Linn (Ed.), Educational Measurement (3rd edn). Washington, DC: The American Council on Education and the National Council on Measurement in Education.
Crew, G. & McKenna, B. (1993). Report of an analysis of the writing task. Brisbane: Queensland Board of Senior Secondary School Studies.
Cronbach, L. J. (1988). Five perspectives on validity argument. In H. Wainer (Ed.), Test validity. Hillsdale, New Jersey: Lawrence Erlbaum Associates.
Cronbach, L. J. (1990). Essentials of psychological testing (5th ed.). New York: Harper Collins.
Gilmer, J. S. & Feldt, L. S. (1983). Reliability estimation for a test with parts of unknown lengths. Psychometrika, 39(4), 491-499.
Horst, P. (1951). Estimating total test reliability from parts of unequal length. Educational and Psychological Measurement, 11, 368-371.
Linn, R. L. (Ed.) (1989). Educational measurement. Washington, DC: The American Council on Education and the National Council on Measurement in Education.
Linn, R. L. (Ed.) (1993). Linking results of distinct assessments. Applied Measurement in Education, 6(1), 83-102.
Masters, G. N. & McBryde, B. (1994). An investigation of the comparability of teachers' assessment of student folios. Brisbane: Queensland Tertiary Entrance Procedures Authority.
Matters, G. N. (1991). A design process for constructing the Queensland Core Skills Test. Brisbane: Queensland Board of Senior Secondary School Studies.
Matters, G. N. & Gray, K. R. (1994). The Queensland core skills test: implications for the mathematical sciences. Unicorn, 21(4), 74-89.
Maxwell, G. S. (1987). Scaling school-based assessments for calculating overall achievement positions. Appendix 1 in J. Pitman (Chair), Tertiary Entrance in Queensland: A review (Report of the Working Party on Tertiary Entrance) (pp. 190-200). Brisbane: Queensland Board of Secondary School Studies. [Also in The Tertiary Entrance Score - A Technical Handbook of Procedures. Brisbane: Queensland Board of Secondary School Studies, 1988, pages 44-52.]
Maxwell, G. S. (1996). Calculating OPs and FPs: Some questions and answers. Brisbane: Queensland Tertiary Entrance Procedures Authority.
Maxwell, G. S. (1997). A systems analysis of selection for tertiary education: Queensland as a case study. Brisbane: The University of Queensland. (PhD thesis).
McMeniman, M. (1986). A standards schema. Discussion Paper No. 6. Brisbane: Queensland Board of Secondary School Studies Assessment Unit.
Moss, P. A. (1992). Shifting conceptions of validity in educational measurement: implications for performance assessment. Review of Educational Research, 62(3), 229-258.
Moss, P. A. (1994). Can there be validity without reliability? Educational Researcher, 23(2), 5-12.
O'Brien, J. E., Pitman, J. A. & Matters, G. N. (1996). Internal-consistency reliability measures for a test comprising three modes of assessment: Multiple-choice, constructed response and extended writing. Brisbane: Queensland Board of Senior Secondary School Studies.
O'Connor, C. & Robotham, M. A. (1991). Towards equity in the Queensland core skills test: The Queensland sensitivity review process. Brisbane: Queensland Board of Senior Secondary School Studies.
Phillips, D. C. (1990). Subjectivity and objectivity: an objective inquiry. In E. W. Eisner & E. Peshkin (Eds), Qualitative inquiry in education: The continuing debate. New York: Teachers College Press.
Pitman, J. A. (1993). The Queensland Core Skills Test: In profile and in profiles. Paper presented at the 19th Annual Conference of the International Association for Educational Assessment. Mauritius.
Popham, W. J. (1987). The merits of measurement-driven instruction. Phi Delta Kappan, May, 679-682.
QBSSSS. (1992a). What about the QCS test? Brisbane: Queensland Board of Senior Secondary School Studies.
QBSSSS. (1992b). Technical features of the OP/FP system. Brisbane: Queensland Board of Senior Secondary School Studies.
QBSSSS. (1992c). The 1992 QCS test. Brisbane: Queensland Board of Senior Secondary School Studies.
QBSSSS. (1994). The 1994 QCS test. Brisbane: Queensland Board of Senior Secondary School Studies.
Scriven, M. (1972). Objectivity and subjectivity in educational research. In L. G. Thomas (Ed.), Philosophical redirection of educational research. Chicago: University of Chicago Press.
Travers, E. J. & Allen, J. R. (1994). Random sampling of student folios: A pilot study. Brisbane: Queensland Board of Senior Secondary School Studies.
Vernon, P. E. (1964). The Certificate of Secondary Education: An introduction to objective-type examinations. London: Secondary School Examinations Council.
Viviani, N. (1990). The Review of Tertiary Entrance in Queensland 1990. Brisbane: Queensland Department of Education.
Welch, C. & Hoover, H. D. (1993). Procedures for extending item bias detection techniques to polytomously scored items. Applied Measurement in Education, 6(1), 1-19.
Wood, R. (1991). Assessment and testing: A survey of research commissioned by the University of Cambridge Local Examinations Syndicate. Cambridge: Cambridge University Press.
| Author details: All three authors are officers of the Queensland Board of Senior Secondary School Studies (QBSSSS). Gabrielle N. Matters is Deputy Director (Testing & Publishing), John A Pitman is Director and John E. O'Brien is Assistant Director (Moderation). Address for correspondence: PO Box 307, Spring Hill, Qld, Australia 4004. Phone: 07 3864 0258; Fax: 07 3221 2930
Please cite as: Matters, G., Pitman, J. and O'Brien, J. (1998). Validity and reliability in educational assessment and testing: A matter of judgement. Queensland Journal of Educational Research, 14(2), 57-88. http://education.curtin.edu.au/iier/qjer/qjer14/matters.html |